
Exploring Lumiere A Deep Dive into Advanced Video Generation
In the fast-evolving world of artificial intelligence and machine learning, a new milestone has been achieved with the development of “Lumiere.” This state-of-the-art model represents a quantum leap in video generation, transforming the way we create and perceive digital content.
What Sets Lumiere Apart?
Lumiere isn’t just another video generation tool; it’s a groundbreaking approach that changes the fundamentals of how videos are synthesized. This model, developed by a team of researchers at Google Research, Weizmann Institute, Tel-Aviv University, and Technion, employs a novel Space-Time U-Net (STUNet) architecture. Unlike traditional models that generate keyframes and then fill in gaps, Lumiere processes the entire video sequence in one comprehensive step. This method ensures a more fluid and natural motion, a critical aspect often lacking in previous technologies.
The Technical Brilliance of Lumiere
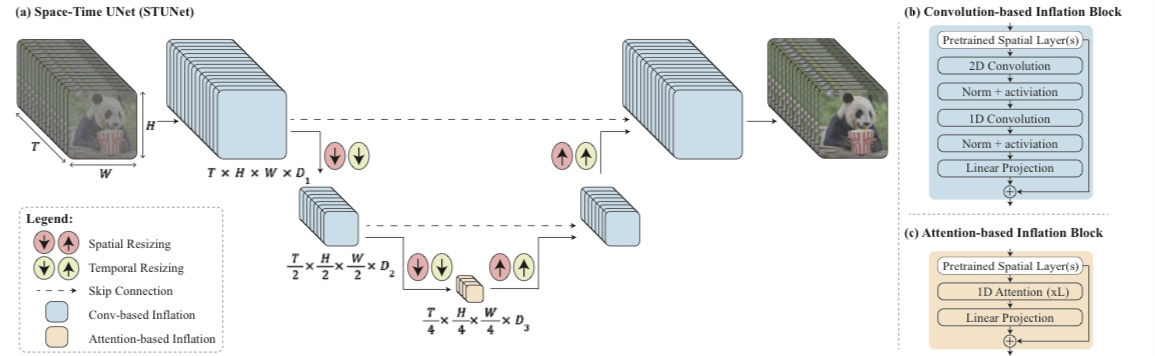
Image Source: Bar-Tal, Omer; Chefer, Hila; Tov, Omer, et al. "Lumiere: A Space-Time Diffusion Model for Video Generation." arXiv, 2024. [arXiv:2401.12945]
At its core, Lumiere’s STUNet architecture is a marvel of engineering. It uses sophisticated spatial and temporal down- and up-sampling techniques, allowing the model to handle videos at various space-time scales. This capability is crucial for creating high-resolution, full-frame-rate videos without compromising on quality. Moreover, Lumiere integrates a pre-trained text-to-image diffusion model, a feature that significantly enhances its ability to interpret and convert textual prompts into coherent video sequences.
Advantages Over Traditional Models
- Global Temporal Consistency: Lumiere stands out in its ability to produce videos with globally coherent motion. This consistency is especially evident in complex scenes with repetitive or periodic movements.
- Enhanced Efficiency and Reduced Training Complexity: By eliminating the need for cascaded temporal super-resolution, Lumiere streamlines the video generation process, making it more memory-efficient and easier to train.
- Bridging the Domain Gap: Traditional models often struggle with a domain gap, where the interpolation of generated frames leads to inconsistencies. Lumiere tackles this by consistently generating videos from start to finish, enhancing the overall quality and realism.
Lumiere’s Versatile Applications
The implications of Lumiere’s technology extend far beyond basic text-to-video generation:
- Image-to-Video Conversion: Imagine turning a single still image into a dynamic, moving scene. With Lumiere, this becomes a reality, opening doors to new forms of storytelling and digital art.
- Video Inpainting: Lumiere can seamlessly repair and restore parts of a video, a valuable tool for historical video restoration or enhancing existing footage.
- Stylized Video Creation: Users can adapt Lumiere to generate videos in specific styles, from hyper-realistic to abstract, catering to diverse creative needs.
- Streamlined Video Editing: The model’s unique approach allows for more coherent and efficient video editing, streamlining post-production workflows.
The Future with Lumiere
Lumiere is not just a technological achievement; it’s a catalyst for a new era in digital content creation. Its ability to generate lifelike, temporally consistent videos opens up a universe of possibilities in storytelling, content creation, and beyond. As the model continues to evolve, we can expect to see even more innovative applications and improvements.
Conclusion
Lumiere represents a significant step forward in the world of video generation. It’s a testament to the incredible potential of AI and machine learning in reshaping the creative landscape. As we continue to explore Lumiere’s capabilities, we stand on the brink of a new dawn in digital creativity, where the boundaries between text, images, and videos become ever more seamless.
Looking for prompts? We have the world's best prompts here.
Want more blogs? Find more here.
Full credit to: Bar-Tal, Omer; Chefer, Hila; Tov, Omer, et al. "Lumiere: A Space-Time Diffusion Model for Video Generation." arXiv, 2024. [arXiv:2401.12945]

About the Author
Stephen is the founder of The Prompt Index, the #1 AI resource platform. With a background in sales, data analysis, and artificial intelligence, Stephen has successfully leveraged AI in order to build a free platform that helps others integrate artificial intelligence into their lives. Connect with him on LinkedIn or Telegram.