Large Language models (LLMs) like GPT-3/GPT-4/Claude-3 and others have exhibited astonishing capabilities across various domains, from mathematical problem-solving to creative writing. However, there's been an inherent limitation in their approach – the left-to-right, token-by-token decision-making process, which doesn't always align with complex problem-solving scenarios that demand strategic planning and exploration.
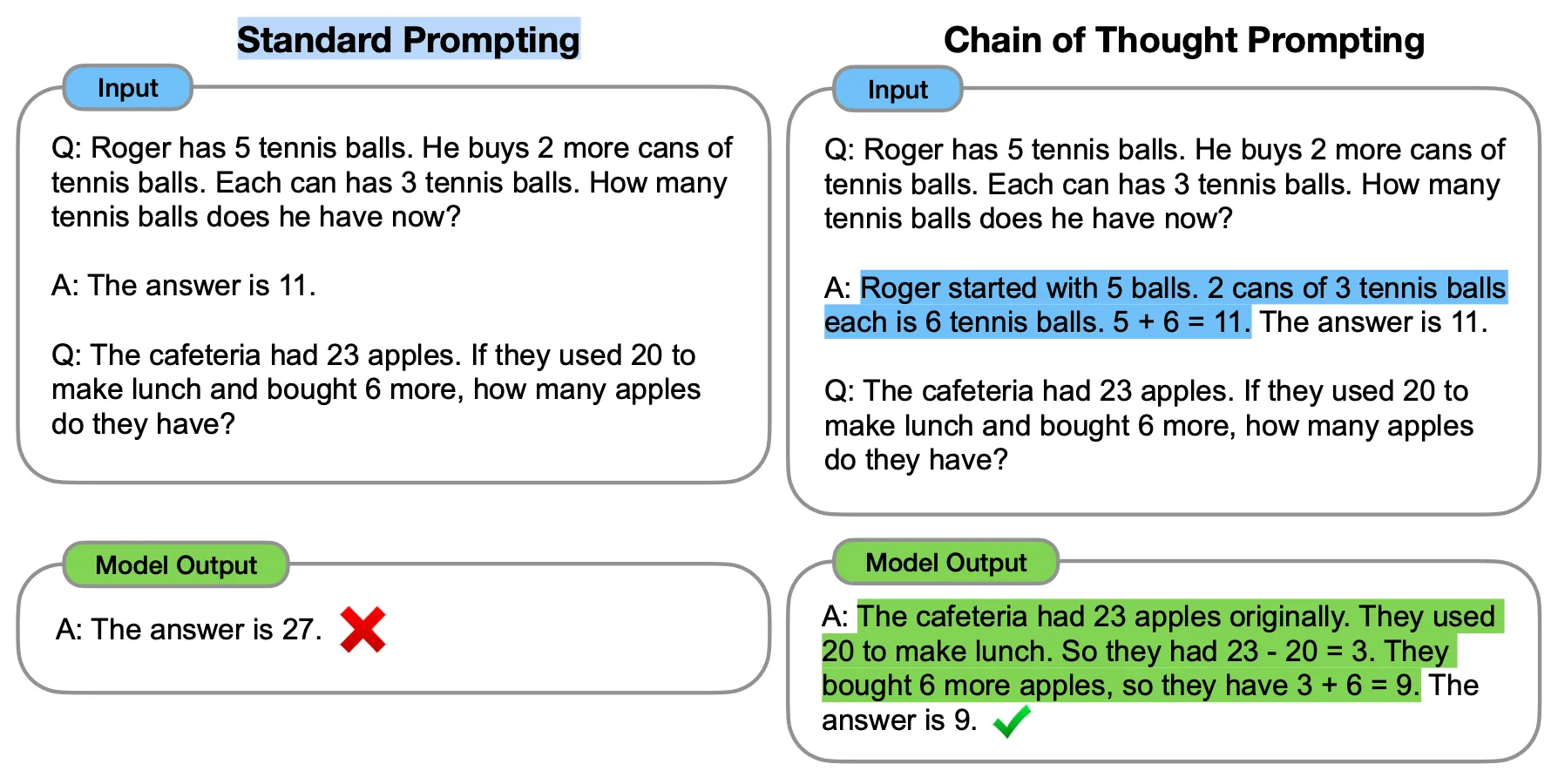
But what if we could enable these LLMs to think more strategically, explore multiple reasoning paths, and evaluate the quality of their thoughts in a deliberate manner? Some researchers have created a framework called "Tree of Thoughts" (ToT) which aims to fix this by enhancing the problem-solving prowess of large language models.
The Essence of ToT
At its core, ToT reimagines the reasoning process as an intricate tree structure. Each branch of this tree represents an intermediate "thought" or a coherent chunk of text that serves as a crucial step toward reaching a solution. Think of it as a roadmap where each stop is a meaningful milestone in the journey towards problem resolution. For instance, in mathematical problem-solving, these thoughts could correspond to equations or strategies.
But ToT doesn't stop there. It actively encourages the LM to generate multiple possible thoughts at each juncture, rather than sticking to a single sequential thought generation process, as seen in traditional chain-of-thought prompting. This flexibility allows the model to explore diverse reasoning paths and consider various options simultaneously.
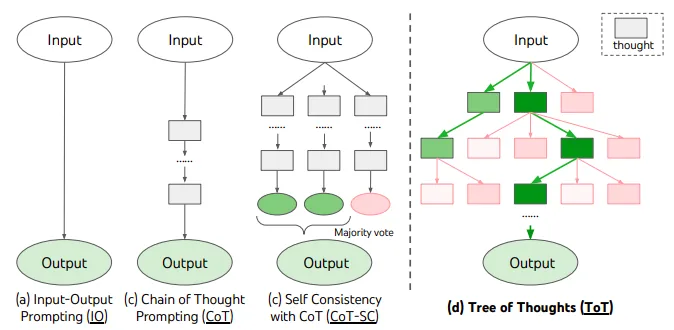 Image Source: Yao et el. (2023)
Image Source: Yao et el. (2023)
The Power of Self-Evaluation: One of ToT's defining features is the model's ability to evaluate its own thoughts. It's like having an inbuilt compass to assess the validity or likelihood of success for each thought. This self-evaluation provides a heuristic, a kind of mental scorecard, to guide the LM through its decision-making process. It helps the model distinguish between promising paths and those that may lead to dead ends.
Systematic Exploration: ToT takes strategic thinking up a notch by employing classic search algorithms such as breadth-first search or depth-first search to systematically explore the tree of thoughts. These algorithms allow the model to look ahead, backtrack when necessary, and branch out to consider different possibilities. It's akin to a chess player contemplating multiple moves ahead before making a move.
Customisable and Adaptable: One of ToT's strengths is its modularity. Every component, from thought representation to generation, evaluation, and search algorithm, can be customized to fit the specific problem at hand. No additional model training is needed, making it highly adaptable to various tasks.
Real-World Applications: The true litmus test for any AI framework is its practical applications. ToT has been put to the test across different challenges, including the Game of 24, Creative Writing, and Mini Crosswords. In each case, ToT significantly boosted the problem-solving capabilities of LLMs over standard prompting methods. For instance, in the Game of 24, success rates soared from a mere 4% with chain-of-thought prompting to an impressive 74% with ToT.
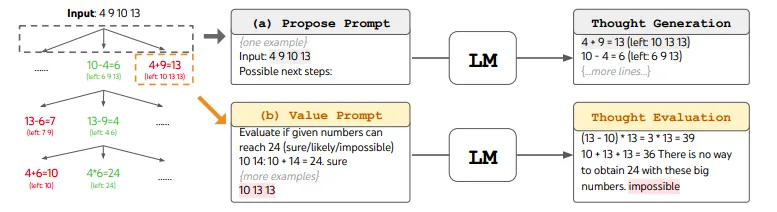 Image Source: Yao et el. (2023)
Image Source: Yao et el. (2023)
The above image is a visual representation of the Game of 24 which is a mathematical reasoning challenge where the goal is to use 4 input numbers and arithmetic operations to reach the target number 24.
The tree of thought (ToT) approach represents this as a search over possible intermediate equation "thoughts" that progressively simplify towards the final solution.
First, the language model proposes candidate thoughts that manipulate the inputs (e.g. (10 – 4)).
Next, it evaluates the promise of reaching 24 from each partial equation by estimating how close the current result is. Thoughts evaluated as impossible are pruned.
The process repeats, generating new thoughts conditioned on the remaining options, evaluating them, and pruning. This iterative search through the space of possible equations allows systematic reasoning.
For example, the model might first try (10 – 4), then build on this by proposing (6 x 13 – 9) which gets closer to 24. After several rounds of generation and evaluation, it finally produces a complete solution path like: (10 – 4) x (13 – 9) = 24.
By deliberating over multiple possible chains of reasoning, ToT allows more structured problem solving compared to solely prompting for the end solution.
A Glimpse into the Future
As we delve deeper into the era of AI-driven decision-making, the ToT framework represents a pivotal development. It bridges the gap between symbolic planning and modern LLMs, offering the promise of more human-like planning and metacognition. This opens exciting possibilities for better aligning AI with human intentions and understanding.
Conclusion
In conclusion, the Tree of Thoughts (ToT) framework is a beacon of light in the AI landscape. It introduces a level of strategic thinking and exploration that was previously lacking in language models. By allowing LLMs to consider multiple reasoning paths, evaluate their own choices, and systematically explore complex problems, ToT paves the way for more intelligent, adaptable, and effective AI systems. The journey has just begun, and the potential for ToT to reshape the future of AI is boundless.